10
Automating the Conversion of Text Into Hypertext
Introduction
Computer users are quick to recognize the benefits of hypertext-based on-line documentation: ease of use and rapid access of information.
Most are not aware of the considerable effort required to transform existing linear text into hypertext. The high initial cost of creating hypertext and the recurring cost of maintaining it limits its availability. Only when the creation and maintenance of hypertext is automated will it become accessible to a much larger audience.
This chapter discusses the conversion of existing text into hypertext.
Most hypertext authoring tools, used manually to originate and link text, are useful for creating small hypertext applications but lack productivity- enhancing tools when linking large amounts of text.
Existing text (hardcopy or electronic) may require processing before being converted into hypertext. The following section describes tools for preprocessing text so that it can be linked. This chapter includes sections which describe how hypertext links are created manually; technologies for computer assisted linking; and alternate strategies for improving the conversion process. Some of the techniques and strategies discussed describe SmarText, a commercially available conversion tool. Finally, an important development is discussed that will influence the future of text-to-hypertext conversion.
A Note On Terminology
Because this chapter deals with conversion of existing linear documents into hypertext, it seemed improper to call the person who supervised this process an author. Products like SmarText don’t change the style or content of pre-existing documents in any way, but they do provide new ways of accessing information. Thus, we use the word “builder” to refer to the one who orchestrates the process by which products like SmarText create hyperdocuments.
Automation of Text Preprocessing
Existing text requires preprocessing if it is incompatible with the conversion utility. If text exists in an electronic form, very little effort may be necessary. But a significant level of effort may be necessary if the text exists only in a hardcopy form that must be scanned and converted into electronic text. In either case, programs exist to automate this preprocessing.
Hardcopy text is transformed into an electronic form by manual keyboard entry
or optical character recognition (OCR). Keyboard entry may be the only option available if the hardcopy text is handwritten, in a nonstandard font or type size, or is illegible.
Optical character recognition involves three steps: scanning, character recognition, and artifact removal. Optical scanners transform hardcopy pages into electronic images. These text images can be stored in a computer and displayed like any other image.
OCR software and/or hardware is used to transform scanned images into ASCII text. In this form the words take up less disk space. Character recognition is usually fastest when performed on specialized hardware but software-based character recognition is usually less expensive.
The optical scanning and recognition process introduces errors or artifacts that must be corrected. Artifacts occur, for example, when the image of a letter “e” is recognized as a “c” or when the image of an “h” is recognized as a “b.”
Specialized editors with integral spelling checkers are available from OCR manufacturers to automate the removal of artifacts. If the character recognition hardware or software is unsure of whether or not it has recognized a letter, it flags the word containing that character. After character recognition, the editor skips from one flagged word to the next, suggesting correctly spelled replacement words if the flagged word does not exist in the editor’s dictionary. This improves the productivity of artifact removal because the user need only accept or reject the editor’s suggested replacements.
The following are likely to reduce the productivity of the hardcopy conversion
effort by increasing the number of artifacts. At some point, it may be cheaper and faster to enter the text manually:
- Kerned text reduces the accuracy of character recognition. Kerning is a practice used by typesetters to improve the appearance of text. Two letters are kerned when one letter made to overhang or come into proximity to the other. Kerning often occurs, for example, when a lowercase vowel follows a capital “T” or “W.” While kerning improves the appearance of text, it reduces the reliability of optical character recognition.
- Nonstandard font sizes and types are not recognized. Recognition systems handle the most common typefaces (e.g., Courier) and font sizes (10 and 12 point). They are useless with very small or large font sizes or fancy fonts such as cursive styles.
- Glossy finish hardcopy documents may reduce the accuracy of character recognition. Glossy hardcopy effectively reduces the contrast of the scanned text. Some scanners are more resistant to this effect than others.
- Text printed on colored or shaded backgrounds may be unreadable. This is because most scanners encode non-white regions as black.
Even if text exists in an electronic form, it may require processing before it can be converted into hypertext. The electronic text may be in a format that is incompatible with the authoring or conversion tool. Examples of potential problems include:
- The text may contain extended, graphic, or otherwise non-ASCII characters not recognized by the conversion tool.
- The termination characters used to denote the end of a line of text or paragraph may be incompatible with the conversion tool.
- The text may exist in a word processor file format that is incompatible with the conversion tool.
Utilities are available for converting various word processor files into ASCII text with line termination denoted by a carriage return and line feed character. Most hypertext authoring or conversion tools can import text in this format.
Methodologies for Defining Links
Before discussing the automation of the conversion process, it is useful to review the different methodologies for organizing linear text into nonlinear hypertext.
Defining Hypertext Links Using Embedded Commands
The links of many hypertext systems are defined by embedding commands in text. This marked-up text may be interpreted by a structured browser or compiled into a hypertext application. There are two types of embedded commands: procedural and declarative.
Procedural languages specify what a link should do: make the next word a link to x. Most hypertext command languages are procedural. For example, HyperTalk is the procedural command language for HyperCard.
Declarative languages specify what a link is: the next line is a chapter heading, or the following paragraph is semantically related to x, y, and z. If declarative commands are used, then a separate file is necessary to describe conventions for linking chapter headings or paragraphs (similar to style sheets found in word processors).
Procedural languages are proprietary and application-specific. In contrast, a declarative markup language can be used in various applications to define hypertext organization, database organization, and hardcopy page layout.
Standard Generalized Markup Language (SGML) is an example of a declarative markup language that can be used for multiple purposes.
The procedural/declarative options need not be mutually exclusive.
SmarText creates a procedural command list from the declarative commands embedded in proprietary word processor source files such as Samna’s Ami Professional. This resulting list of procedural commands is then edited manually or by direct manipulation.
Linking By Direct Manipulation
Linking (text) by direct manipulation (LDM) requires less memorization and recall than more traditional authoring. That makes LDM easy to use by novice or occasional users. LDM is an example of What-You-See-Is-What-You-Get (WYSIWYG) editing [Shneiderman, 1983]. A hypertext link is created in SmarText using direct manipulation the following way:
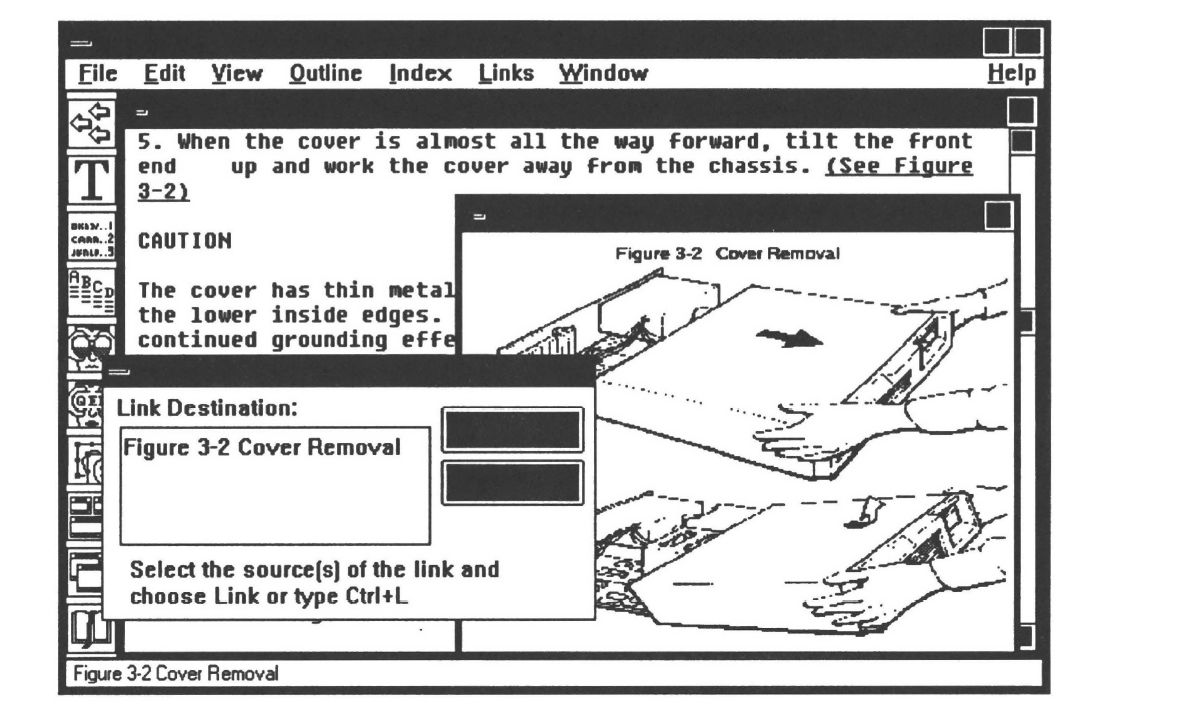
- Select the link destination by clicking on it with a mouse.
- Click on a pull down menu command Create Link. A moveable dialogue box appears containing two buttons, Link and Cancel.
- Select the first link source in the text window by clicking on it with a mouse.
- Click on the Link button of the Create Link dialogue box. A link is created.
- Repeat the third and fourth operations for as many links as desired.
When finished, click on the Cancel button of the Create Link dialogue box.
Although LDM may not be as easy to explain as an embedded command language, it is simple and fast.
Multiple Methodologies For Linking Hypertext
Linking by embedding commands in text and LDM each has its advantages. LDM
prevents the hyperdocument builder from ever introducing syntactical errors, so program debugging is unnecessary.
By requiring less memorization and recall of programming commands, LDM has a shorter learning curve. Yet, embedded com mand linking typically provides a richer and more powerful set of options than does LDM. An embedded command language is necessary if one wishes to auto mate the text-to-hypertext conversion process. Then, one could write a computer program that analyzes text and generates hypertext link commands.
Users get the best of both worlds if authoring or conversion tools support both embedded command programming and linking by direct manipulation. This is accomplished by offering two views of the same hypertext document: WYSIWYG and uncompiled program commands. Guide (version 3.0 for Microsoft Windows), Toolbook, and SmarText are examples of commercial hypertext systems that offer the user the choice of embedded command programming or linking by direct ma nipulation.
Computer-Assisted Link Generation
A more efficient way to define links is to let the computer generate them. Computer-assisted link generation capability may be integrated into a conversion tool or it may be offered as a part of a standalone utility. A standalone utility analyzes the text and then generates link commands. These link commands are then either compiled by the hypertext compiler or interpreted directly by the hypertext engine.
The appendix at the end of this chapter describes a standalone user-written program that generates hypertext links based on lexical string matching. Examples of integrated computer-assisted link generation built into the SmarText Construction Set are discussed later in this chapter.
Additive vs. Subtractive Assistance
An artist sculpts a statue from a block of marble by removing everything irrelevant to the finished piece of artwork. This same approach can speed the sculpting of hypertext if a large percentage of the links suggested by the computer are inappropriate and if links can be deleted much faster than they can be inserted. Suppose a computer program suggests 200 hypertext links and only half of them are appropriate. A person may be able to mark those 100 links for removal (leaving 100 good links) faster than anyone could create 100 links in the first place by embedding commands or by direct manipulation.
The SmarText Construction Set uses this technique for creating internal cross references and a hypertext index, a topic which will be discussed in greater detail later in the chapter.
Technologies for Computer-Assisted Linking
The ideal conversion tool would create hypertext links correctly in text without any human intervention. It is unlikely that such a tool will ever exist since two people rarely agree on what a correct link is. A more realistic goal is a conversion tool that suggests links and creates them upon human confirmation. That is the goal of the technologies discussed below.
The reader should be forewarned: many of the techniques discussed below have not been tested outside of research laboratories. As promising as some may seem, there is no guarantee that they will ever be practical.
A technique may prove impractical because it is too slow, too unreliable, or because it requires too much computer memory.
Lexical Analysis
One approach to computer-assisted linking is based on lexical analysis. In its simplest form, lexical analysis resembles pattern or character string matching. Lexical analysis can be a powerful tool but users must be aware of its limitations.
Synonymy and polysemy both limit the usefulness of lexical analysis. Synonymity occurs when two different words have the same meaning. Polysemy occurs when one word has more than one meaning. One study has shown that people typically use the same word to describe an object only 10 percent to 20 percent of the time. Therefore, automated linking based on keyword matching alone is unlikely to be successful.
Simple character string matching could be used to generate commands to link all instances of a word to the defmition of the word. However, this approach would most likely generate many redundant links. If a word to be linked occurs several times within the same paragraph, only the first instance of that term should be linked. Otherwise, text is likely to become cluttered with redundant hypertext links and readability will suffer. [See Chapter 11 by Shneiderman, et al., in this book.]
Another problem with simple character string matching is the likelihood that it might miss links altogether. Simple string matching cannot discern the many root word variations due to the concatenation of suffixes. Stemming is required to determine if two words share the same root word. A word is stemmed by recursively removing suffixes from the tail end of words until only three or more characters remain. The English language has only about 75 prefixes and 250 suffixes.
There are two approaches to word stemming: heuristic and rule-based. A heuristic approach to stemming can determine a root very quickly by interactively removing suffixes like s, er, ing, and others, from the end of a string until no suffixes remain. This approach works very well for words like compute(s), computer(s), computing, computable, computability, computation, and computational. This approach does not work for words like sable, sing, and seer. The reliability of this algorithm improves if one requires that at least three characters remain in the root. But it will still group the terms cap and capability or cat and catering together. Dictionary-based approaches are slower and occupy more memory than heuristic approaches but they are more reliable. They record the permissible suffixes with each word in a large dictionary. Compiling such a dictionary is time consuming. If a word to be stemmed is not contained within the dictionary, then the algorithm falls back to a heuristic approach.
The appendix to this chapter describes a simple but useful application of lexical analysis for creating a hypertext table of contents from data down-loaded from an on-line database.
Statistical Analysis
Results of statistical analyses of word frequency and distribution throughout a text document can be used to automate the generation of hypertext indexes and internal cross references.
Large on-line database systems that store the text of technical articles often
search for particular articles by comparing the words of a query with word de scriptors that characterize the article. Usually these descriptors are assigned to each text record by subject experts. The process of assigning keyword descriptors to text records is called indexing. Automatic indexing has been studied as a way to create compact keyword descriptions of documents stored and accessed in large text retrieval systems.
The same technology used to index databases can be used to create a hypertext index-similar to the index found in the back of books. However, the objectives for creating an index for text retrieval and for hypertext are different. Database indices discriminate between text records that have well-delineated boundaries. The indices for printed or hypertext documents are meant to help readers locate important topics that are discussed within a body of text that has few or no internal boundaries. Because of these differences, underlying assumptions for generating an index may be different. The following two assumptions apply to hyperdocument indices only:
- Words that occur very frequently or very infrequently within a document are the least likely to be of interest to the reader. By analyzing the statistics of word frequency, one may choose those words that have an intermediate frequency of occurrence. SmarText relies on this assumption.
- There are simply too many useless words that occur with intermediate frequencies and there are many useful words that occur infrequently.
Therefore, by itself, automated indexing based on term frequency is not very useful. Stopword and keyword lists can be used to improve the performance of indexing. A stopword list contains terms that should never be entered into index. A keyword list contains terms that should always be entered into an index if the document contains that word.
Every time SmarText builds an index, it includes a default stopword list containing hundreds of common words. In addition, every time the hyperdocument builder manually deletes a word from a SmarText index, that word is added automatically to a document-specific stopword list.
This stopword list can be reused in building other related documents.
Every time the builder adds a word manually to the index, that word is added automatically to a document-specific keyword list. Like stopword lists, this keyword list can be reused in building other related documents.
Syntactical Analysis
Syntax is used to describe the structure of words in sentences. One of the goals of analyzing sentence syntax is to determine the parts of speech so that meaning can be inferred. For example, whether a word is being used as a noun (high frequency transistor) or as an adjective (high frequency transistor radio) influences its meaning. By identifying how a term is used, a program should be able to differentiate between multiple meanings of the same word. The use of syntax to infer sentence meaning has been the focus of research in natural language processing (NLP) and artificial intelligence (AI) for more than 30 years. Unfortunately, this research has produced few robust or commercially viable products.
Computational complexity and brittleness are two reasons why NLP and AI have had limited commercial success. The amount of processing required in non trivial expert systems based on production rules or deductive retrieval can easily exceed the resources available on personal computers or the patience of users. Brittleness describes the ungraceful degradation of program performance inherent in all symbol-based AI systems. It is a form of unreliability that occurs whenever an AI program encounters a situation that its creator never anticipated. The ability of AI programs to use common sense and to learn from their mistakes depends solely on the cleverness and foresight of their programmers.
The application of syntactical methodologies is discussed in greater detail in [Salton, 1989a; Salton, 1989b].
Syntax can also be used to describe the hierarchical structure of chapter and section units within a complete document. An algorithm is described later in this chapter that infers a hierarchical structure from a document’s text. Although the algorithm is brittle, it reduces the time spent creating a hypertext table of contents.
Semantics
Semantic analysis attempts to create hypertext links based on the explicit meanings or implicit associations (connotations) of terms and phrases [Foltz, 1990]. Semantics is an area of controversy because of disagreement over what meaning is. Lexical, statistical, and syntactical techniques analyze text patterns without regard to what those patterns mean. Programs claiming to perform semantic analysis are based on one or more of those non-semantic approaches. This suggests that meaning is inherently probabilistic or structural in nature-a claim that many disagree with.
Although there is research suggesting that semantic analysis can improve the retrieval of textual information, a significant amount of processing and memory is required and performance improvements are incremental at best [Foltz, 1990].
Alternative Strategies for Improving Productivity
Our goal is to reduce the cost of converting linear text into hypertext by improving the productivity of the process. Computer-assisted linking is a very appealing idea, but it is only one of many ways to expedite the conversion process. Depending on the data being linked and the application, computer-assisted linking may be the least fruitful of productivity-enhancing strategies. The following low technology strategies can significantly reduce the time and effort required to convert text into hypertext.
Prior Planning Prevents Poor Performance
Many electronic documents exist first as hardcopy documents. By anticipating the eventual conversion of a hardcopy document to an electronic form, a lot of manual labor can be avoided. The following are suggestions for those planning to publish in both hardcopy and electronic forms:
- Do not store text with words split up by hyphenations. Utilities exist for splitting whole words into syllables but few utilities exist that can tell the difference between a single word split into two syllables and a hyphenated word (e.g., on-line).
- Use symbolic references to other parts of the document: avoid page number references. Page numbers make little sense for hypertext documents if scrollable text is wrapped and displayed within sizable windows. Instead of page references, refer to chapter headings or descriptive text strings that can be searched.
- Avoid overuse of sidebars. Sidebars resemble footnotes except they tend to contain more text and are embedded in the page in a box of their own. They are examples of nonlinear text since they occur outside of the main text stream. Since they do occur outside of the main text stream, a conversion tool may not know what to do with them (where to link them in), thus requiring a greater manual effort.
- Correct spelling errors. A misspelled word is unlikely to be linked using any of the automation techniques described above.
- Ensure consistency between the table of contents and the embedded heading captions of source text files. During the development of the SmarText Construction Set, we found that it was often best to ignore the table of contents of the printed document because printed tables of contents tended to differ from the chapter headings as they appeared within the text or the hypertext. This is becoming less of problem now that many word processors automatically generate tables of contents based on the text in a document. However, to be on the safe side, SmarText infers document structure directly from the headings embedded in documents.
- Avoid wide multicolumn tables. Pretty much all structured browsers that wrap text within scrollable and sizable windows make a mess of multicolumn tables if those tables are forced to be wrapped. For example, when the document is dis played, its columns may no longer line up. There are two alternatives to forcedwrapping: use narrow tables or provide an application link to a spreadsheet program.
- Provide hints to the conversion tool. SmarText infers chapter headings and their hierarchical structures from many ASCll text files. However, the inference algorithm works best when it is processing text stored in a native word processing format that uses declarative tags. If a tag is available, SmarText will use it. For example, SmarText will assume that a line of text tagged as Heading_2 by Ami Professional is a second level heading.
Preserving and Re-Using Conversion Information
Once one hyperdocument has been built, building subsequent and related hyperdocuments should require less work if information gathered while building the initial document can be reused. The SmarText Construction Set achieves this two ways: 1) stopword and keyword lists created in building one document may be re-used in building subsequent documents, and 2) alternative views of a document can be derived from existing views. Each of these examples is described in the next section.
Automating Simple Recurring Tasks and
User Interface Design
Some recurring tasks, like searching for the next occurrence of a particular word, can be automated with simple macro utilities. Making often-used functions more accessible, as icons for example, reduces the amount of keyboard or mouse activity. Designing the user interface for intuitive yet efficient use may be the most productive way to improve productivity-and one of the most difficult.
The SmarText Electronic Document
Construction Set
This discussion describes version 1.0 of the SmarText Construction Set. The SmarText Electronic Document Construction Set is a software product that automates the creation and browsing of large hypertext documents.
SmarText is a Microsoft Windows application that operates on 80286 and 80386 personal computers. SmarText shipped in September, 1990, and is distributed by Lotus Development Corporation’s Word Processing Division.
The SmarText Electronic Document Construction Set comes in two versions: a builder for creating and browsing hypertext documents and a network-compatible reader or structured browser [Conklin, 1978] for reading only. The builder includes all the features found in the reader but adds manual and automated link editing functions.
Features of the Reader and Builder
The SmarText user interface, shown in Figure 10. 2, relies on a book metaphor to unify its various components conceptually. The implementation of the book metaphor in SmarText is neither as graphical nor as literal as implementations of hypertext products that frame text within file cards or spiral bound notebooks. A metaphor makes new or abstract concepts familiar and understandable by ground ing them on concrete and familiar concepts [See Chapter 11 by Shneiderman, et al., in this book]. If a metaphor is extended too literally, however, it can limit or constrain its target domain. Electronic documentation has different constraints than hardcopy documentation does – just as motion pictures are different from theater. Our goal was to use metaphor to shorten the SmarText learning curve without limiting the medium.
Title page, table of contents (outline), body of text, illustrations, card catalog
(summary) and index are each bounded by a movable, sizable, and scrollable child window. All child windows are constrained within the SmarText application parent window. SmarText allows both readers and builders to place bookmarks, write margin notes, and copy text from the hyperdocument into an ASCII file, then edit it using a built-in editor. All browsing and link editing commands can be invoked via a keyboard or a mouse.
Accelerator keys and an optional, configurable icon bar provide speedy shortcuts for keyboard or mouse users, respectively.
SmarText documents, like most books, can be browsed several ways. Readers can scroll text linearly within a node. Or, readers can select cross references, de noted by highlighted text, to link to other text locations, illustrations, or executable programs. The act of selecting a link in the outline, index and search results windows causes the text window to change.
The outline window displays an on-line analog of a table of contents.
When a reader clicks on a chapter or section heading in the outline window, the text window becomes the topmost child window and displays the beginning of that chapter or section. The outline window looks and operates like many outlining programs: top level headings hide lower level headings until they are expanded to display lower level headings.
Figure 10.3 shows the text and outline windows tiled within a SmarText application (parent) window.
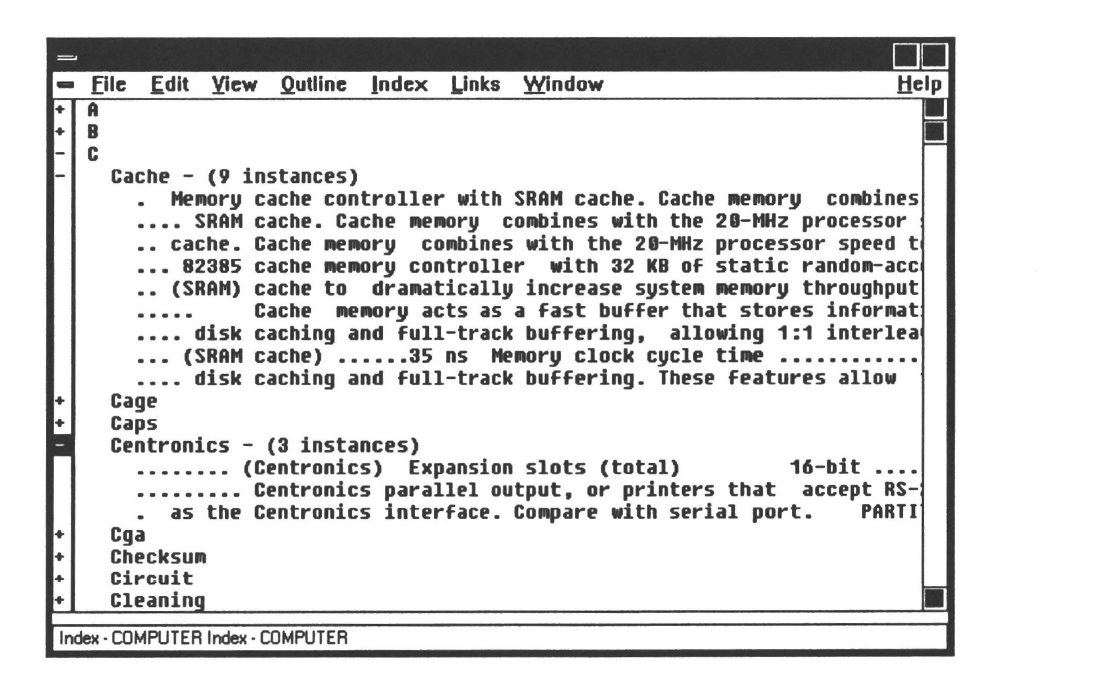
Word entries of the index window expand into KeyWord-In-Context (KWIC) hypertext links. Word-stemming is performed automatically. Double clicking on a KWIC phrase causes the text window to scroll to the location of that phrase. By seeing the word used in context, the reader can better decide which instance of a word is of interest. Figure 10.4 shows the index window maximized. When the reader double clicks on a KWIC phrase, the text window that contains the KWIC phrase becomes the topmost child window.
Boolean search is provided for full text search of one-, two-, or three-word phrases. The results of a search are displayed in a search results window. The search results resemble the KWIC phrases of the index window.
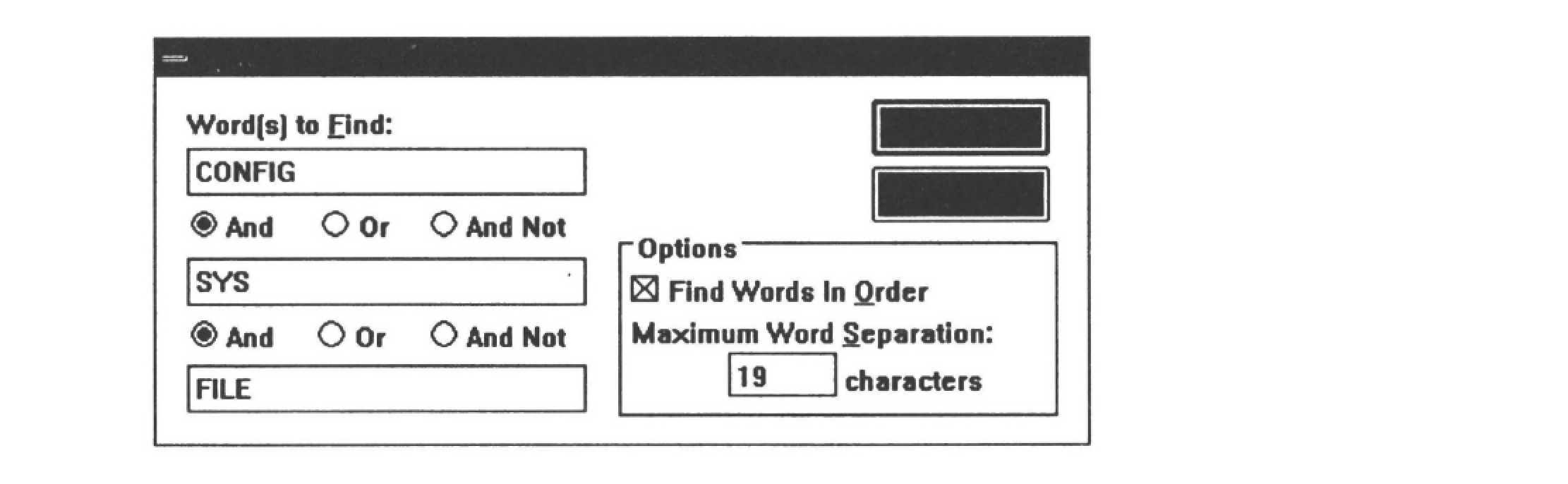
The search dialogue box is shown in Figure 10.5; the search results windows is shown in Figure 10.6.
How SmarText Presents Nonlinear Text
SmarText is intended to be used by novice or casual readers as well as expert users. A criticism often heard of hypertext is that readers become disoriented or lost in hyperspace. SmarText presents nonlinear text in a way intended to minimize reader disorientation.
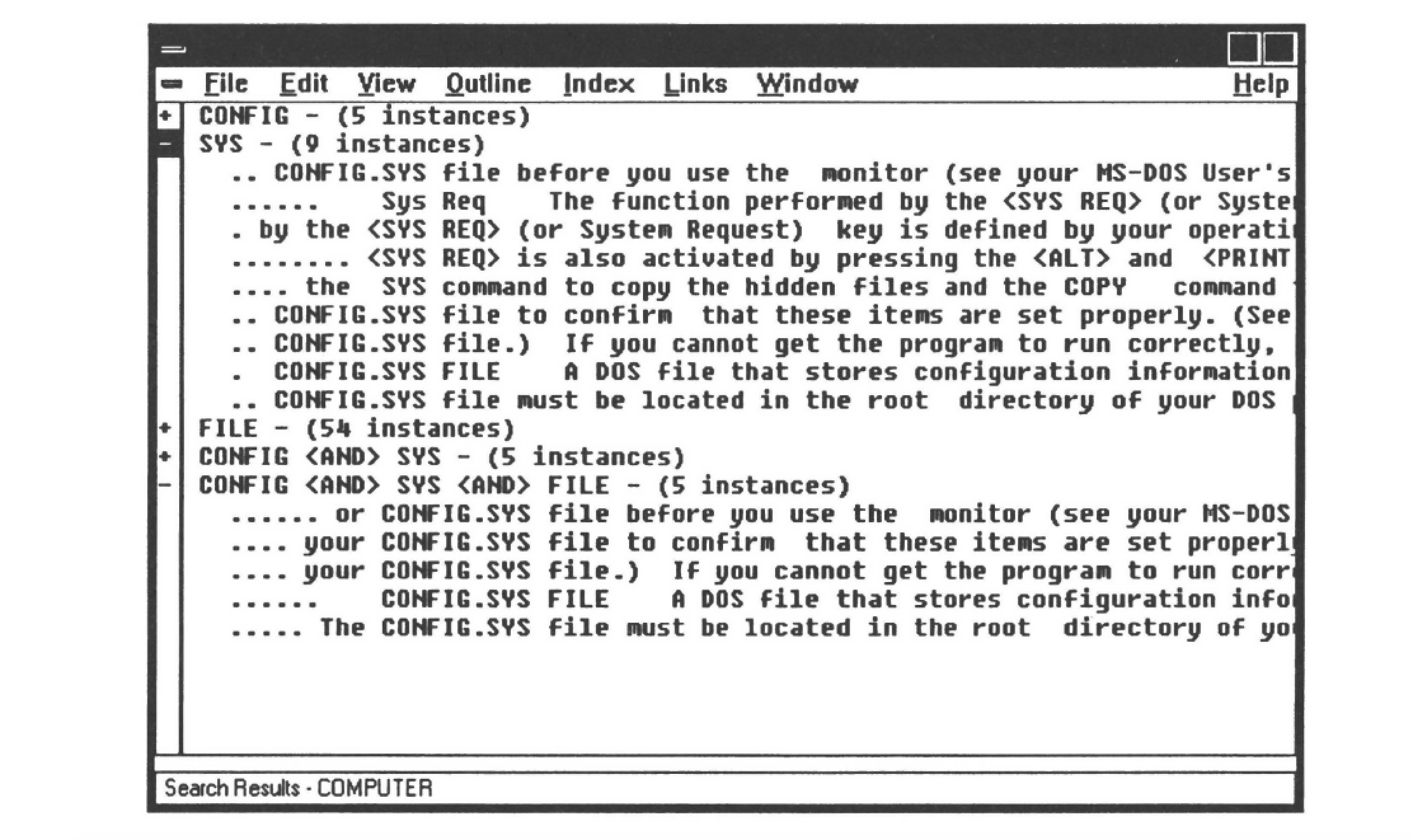
Some hypertext systems model the nonlinearity of text as a network of connected nodes containing text. These nodes typically represent both a physical unit of text (a file) and a logical unit of text (everything that appears on screen). The act of following a link from one node to the next may be represented to the reader in one or more of the following ways:
- Replacing one card by another card
- Replacing the contents of a scrolled window
- Adding a window
- Replacing a text string inline with another text string
Each of these approaches deprives the reader of a sense of Gestalt-a sense of the document’s boundaries and the reader’s location in the text with respect to those boundaries. This lost sense of place may account for some of the disorientation common to readers of hyperdocuments.
SmarText, by contrast, offers multiple views of text presented linearly. SmarText readers select a View in order to choose to traverse one path out of many possible paths. The text, index, and outline windows are constrained by the selected view. The SmarText reader is constantly reminded of a view’s boundary in four ways:
- The slider of the scroll bar shows the view’s boundary and reader’s relation to it.
- A number on the status bar indicates the percentage of the view traversed (one percent to 99 percent).
- The outline window provides a hierarchical description of the entire view.
- The rate at which the slider moves along the scroll bar while one is scrolling or paging gives the reader a sense of the amount of text in the view.
Document Physical & Logical Organization
The logical presentation of text by SmarText is independent of its physical organization. A single SmarText document may reference over five hundred source text files. SmarText never modifies or duplicates text or graphics data. SmarText translates text stored in native word processor formats on-the-fly. This reduces the stor age overhead of maintaining hardcopy and electronic forms of documentation and insures that both forms are consistent with each other.
Since SmarText is a fine-grained system (pointers address characters, not chunks of text), a nodal model is irrelevant. A view may organize sentences, para graphs, or whole files into any arbitrary linear order or hierarchical structure. One view can be a small, simplified extract of another view. By separating logical and physical organization, the hypertext user has a wide range of options for constructing alternative views or browsing paths through text and graphical data.

Inference of Table of Contents
SmarText automates the construction of a hypertext table of contents (outline) by inferring chapter and section headings from the source text files. If the source text file is in an ASCII or simple word processor format, then SmarText analyzes the syntax of each line with respect to the following cues: 1.) line length, 2.) indentation, 3.) capitalization 4.) heading structural cues. Heading structural cues consist of alphabetic letters and Roman or Arabic numerals combined by punctuation marks such as a period (.) or dash(-). SmarText uses a proprietary algorithm to infer the syntax of heading structural cues since there is no common convention for denoting heading hierarchical structure.
Some word processors, such as Ami Professional, store text in a declarative, marked up form. In this case, text that is a title, top level heading, or second level heading is typically marked as such. SmarText uses these mark-up tags to improve the reliability of the algorithm that infers document structure (see Figure 10.7).
SmarText currently uses the descriptive tags found in Samna’s Ami and Ami Professional word processors to build document outlines. Some manual editing of the inferred outline is almost always required. A SmarText builder can easily delete, insert, and promote or demote outline captions (move them up or down a hierarchical level) by direct manipulation. The builder can also change the logical order of headings from within custom views. Swapping the order of two headings in an outline results in the logical swapping of their associated text within the text window. SmarText never modifies source text or graphics files.
Automated Index Generation
SmarText creates an on-line index with keyword-in-context (KWIC) links automatically using the automatic indexing algorithm discussed previously. The approach is summarized below (the actual implementation is different):
- Find all unique words in a document.
- Group words that share a common root together.
- Remove words that also occur in specified stopword lists if they do not also occur in any specified keyword lists (keywords always take precedence over stopwords).
- Remove words that occur most or least frequently (the builder may adjust the threshold levels) that do not occur in any keyword lists.
- For each word, insert a procedural command into an ASCII file (called a shadow file in SmarText). This command will instruct SmarText to add that word to the index window.
- Compile the ASCII command file to generate an underlying data structure to speed browsing.
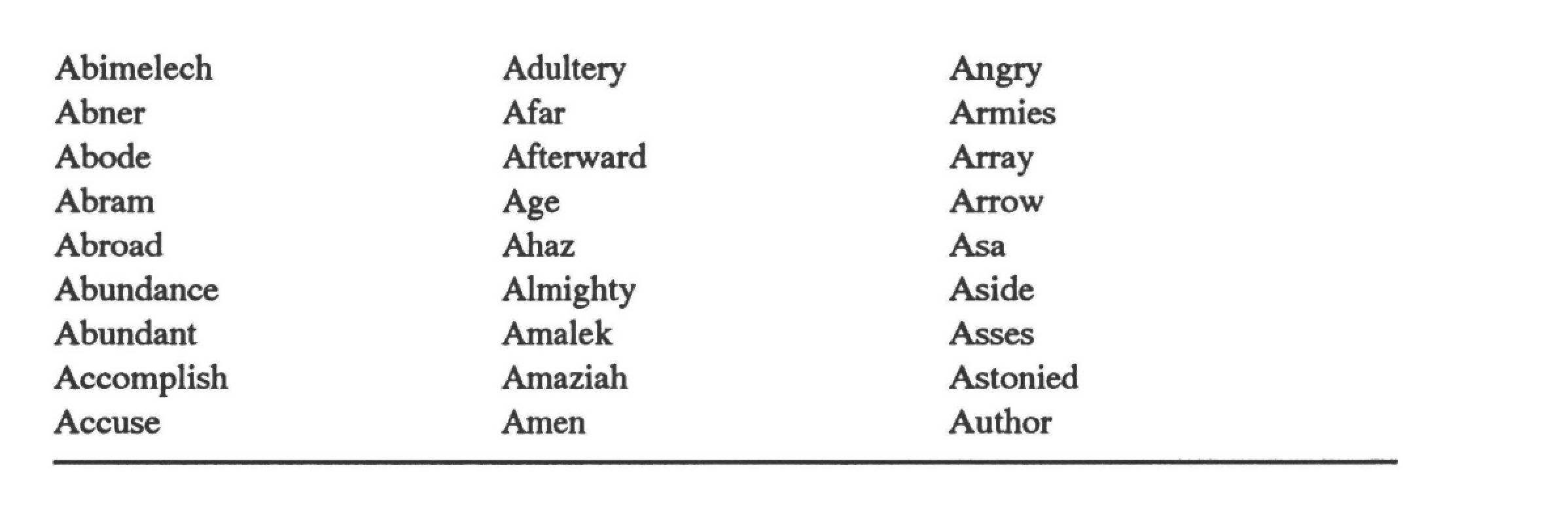
The listing in Table 10.1 shows all the index words beginning with “a” that SmarText extracted from the King James Version of the Bible. The index was built using only the default stopword list containing about three hundred words common in North American English. (The results are presented before any words were excluded by a builder.) The use of subject-specific keyword and stopword lists would improve this result.
Typically, numerous poor choices for index words are made by the algorithm on the first try. The builder deletes those words by marking (clicking on) those words to be deleted and depressing the Delete key. Deleted words are automatically placed on the default document’s stopword list. That stopword list may be used again when building other documents.
The builder may manually add words to the index by invoking an Add Word to Index function or by adding the word to the keyword list and regenerating the index.
Inference of Internal Cross References
SmarText infers hypertext cross reference links within the text window.
The goal of automated cross reference generation is to identify paragraphs that discuss meaningful terms in detail, then to link outlying instances of those terms to the detailed paragraphs. The technique is based on a simple heuristic: if multiple instances of a meaningful word are clustered within a paragraph, then the subject of that paragraph is semantically close to the term itself. SmarText assumes that a word is meaningful if it is listed in the index. The algorithm is summarized below:
- Determine which index words have instances that occur in tightly packed clusters within the text. These become the cross reference terms.
- For each cross reference term, create a link from each solitary instance of the term to the first instance of that word occurring in a cluster of term instances.
- If there are multiple clusters of instances, create a link from the first word instance in a cluster to the first instances in the next cluster.
- Repeat the third step until the last cluster is linked to the first.
The SmarText builder can control the number of cross reference links generated. The algorithm used to determine if index terms are clustered is proprietary.
Sometimes SmarText makes poor choices for cross references. This would happen, for example, if the word teaspoon or its abbreviation tsp. appeared in the index of an on-line cookbook. Teaspoon would probably become an internal cross reference because the word occurs several times in close proximity in the ingredi ents list of many recipes. However, teaspoon would be a poor choice as a cross reference link because it is rarely the subject of a paragraph.
Most index words do not get cross referenced. However, cross reference links can be generated automatically for any index word. The Auto Link dialogue box, shown in Figure 10.8, allows the builder to delete all cross reference links for an index term or to force the generation of cross reference links for one or more index terms. Errors introduced by Auto Link function can be edited manually.
Automated Construction of Views
SmarText’s text and outline windows define a view or logical organization of the document. SmarText infers one view based on the physical text files. In addition, SmarText document developers may define alternative logical views. The logical organization of a custom view is completely independent of the document’s physical organization. In fact, the captions for alternative views need not exist in the original text at all.
There are three ways to construct an alternative view: manually, based on an existing view, and based on cross reference links.
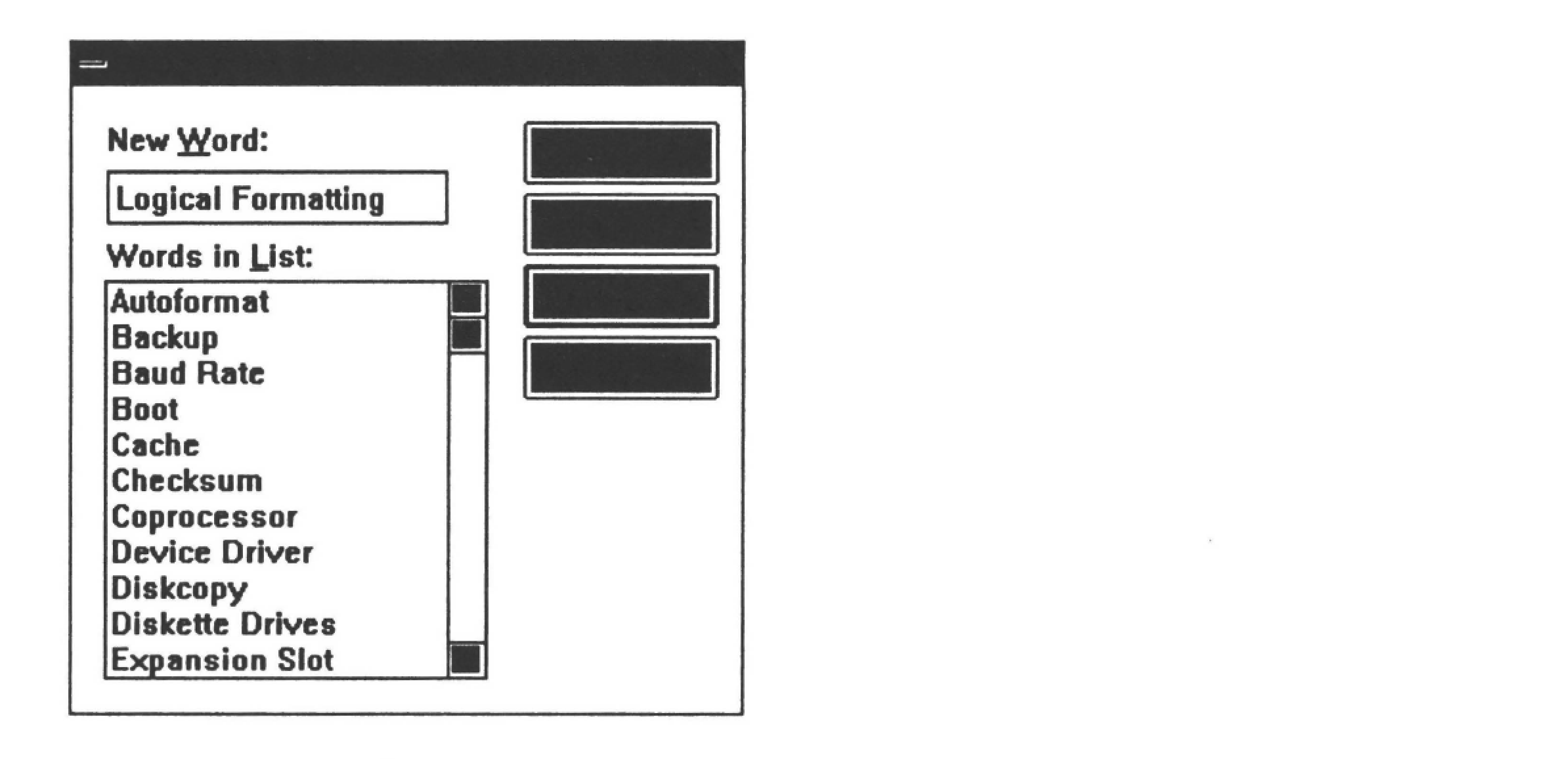
Figure 10.9 shows a dialogue box for creating new views. To create a new view manually:
- Using the mouse or keyboard, select text within the text window corresponding to a chapter or section unit. The first line of selected text becomes the default chapter or section caption in the outline window.
- Edit the caption if necessary.
- Continue the first two steps and until all section captions and section text units are collected.
- Edit the order and hierarchical levels of captions in the outline window. Changing the order of these captions effectively changes the order of text within the text window.
A new view can be created from an existing view. In this case, the new view begins as an exact copy of an existing view. Outline captions in this copied view can be removed, reorganized, and edited by direct manipulation.
The third way to create an alternative view is to base it on one or more index
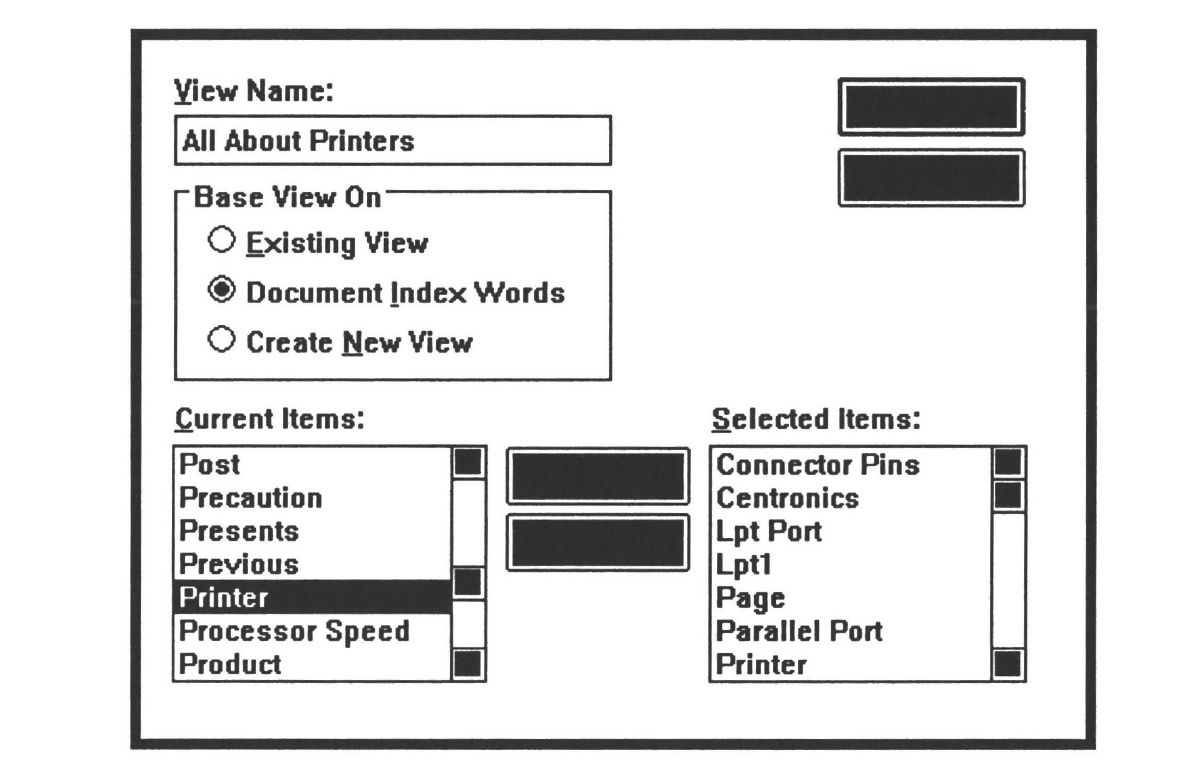
words. In this case, SmarText locates text where selected index words are clustered, selects the text, and inserts them into the new view just as you would manually insert it. Figure 10.9 illustrates the creation of a view called All About Printers based on a list of selected index words: connector pins, Centronics, LPT port, and so on. SmarText locates all paragraphs that contain multiple instances of these index words and appends them together into the text window. SmarText then creates an outline whose captions are the first line from each paragraph (usually these are poor captions, but easy for builders to change).
Support for Document Revision
The time and effort required for revising documents is a significant part of documentation life cycle costs. The cost of using outdated documentation can be devastating. On-line documents must preserve link information during revisions or else document revision becomes even more time consuming.
Preserving links during text revisions is easy if link commands are embedded in the text itself. However, SmarText stores link information (in the form of physical pointers) apart from the source text files. If a source file is edited, then the pointers become meaningless. To avoid losing links, SmarText gives the builder an option to save additional (text string) data that will be used solely for reconstructing existing links. Even so, links may be lost if there is significant cutting and pasting of text.
SGML and the Future of Text-to-Hypertext
Conversion
The increasing acceptance and availability of the Standard Generalized Markup
Language (SGML) as a standard for page markup will have the single greatest influence on the automated conversion of text into hypertext [Bryan, 1988]. SGML is an international standard for document representation. Its scope is publishing in the broadest sense-from hardcopy documents to multi-media database publishing. SGML is being drafted [ISO 8879] by the International Organization for Standardization [Goldfarb, 1986].
SGML simplifies the conversion of text into hypertext because the descriptive tags embedded in SGML files will aid in the conversion process.
The ASCII character set is currently the most common data type shared by word processors, electronic spreadsheets, and database programs. SGML en codes many of the structural relationships in data that are lost importing or exporting ASCII data. Someday, users will export data from a spreadsheet to an SGML format then import that SGML data into a desktop publishing (DTP) system. Conversion filters exist that do this now, but without a common data exchange standard, many more filters need to be written in order to handle all data formats.
SGML is a meta-language. It does not define a specific markup language but an abstract syntax for defming such a language. This frees it from dependency on character sets, national language biases, computer systems and devices. Since SGML is intended to be an unambiguous, formal specification, it can be manipu lated by computer programs as well as humans. SGML is largely a declarative (descriptive) language, though it does provide for procedural (processing) commands.
SGML will blur the differences between corporate managers of publication and
information systems. This is because documents defined using SGML will exist in paper and electronic forms (see Figures 10.10 a and b).
Example of Automated Link Generation
Note: The following example illustrates how links in a large SmarText hypertext application are created automatically independent of built-in conversion tools. This is important because conversion utilities built into products like SmarText cannot automate the conversion of all possible text formats. The example application described below is both useful and practical.
Special interest conferences or forums are valuable services provided by online database services such as BIX or Compuserve. Electronic forums enable users of a particular product to seek help from others and to share ideas, complaints, data, and utilities. Forums are a valuable source of information to the company whose product is the focus of the forum. Forums provide that company with information that aids marketing, product development, product support, and engineering.
How can information downloaded from a forum be distributed throughout a large organization efficiently and cost effectively? Downloaded data is usually poorly organized, has a very short useful lifetime, and may amount to several megabytes each month.

A solution to this problem is to construct a hypertext document that can be browsed from a personal computer on a local area network or from a shared dedicated personal computer. (Note: One problem not addressed in this example is the potential for violating the on-line database company’s copyright.)

Let’s look first at the raw text data down loaded from an imaginary on-line service. The following messages are characteristic of messages downloaded from a user’s forum devoted to an imaginary hypertext product called HyperHype:
#: 6861 S99/HyperHype
06-Jun-90 18:40:30
Sb: video drivers
Fm: Jim Fripp 12345,6789
To: all
the video driver for the ACME video board is now available
for HyperHype from their bbs.
415-968-1234
download is approx. 20 minutes at 2400.
jim
#: 6862 S99/HyperHype
06-Jun-90 18:44:26
Sb: Help needed converting graphics files
Fm: Kelly Wallabee 98765,43
To: All
How come the one graphic format that HyperHype supports
isn't compatible with any other known format? Doesn't that
seem strange to anyone? Is there an HHP to TIFF converter
out there?
* Kelly
There is 1 Reply.
#: 7205 S99/HyperHype
07-Jun-90 09:51:41
Sb: #6862-HHP to TIFF conversion utility
Fm: Rex Ponderosa 34567,8901
To: Kelly Wallabee 98765,43
The HyperHype folks will sell you a PIC-HHP graphics
conversion utility for $995. If your graphics are in any
other format, then you'll need another graphic conversion
utility to get it into PIC format first.
Good luck.
* Rex
It is unreasonable to expect anyone to scroll through several megabytes of data like this. Browsing a table of contents is a more reasonable way to scan a large amount of text. Unfortunately, SmarText (version 1.0) cannot recognize the subject of each message even though it seems this would be a simple task. A message’s subject follows the Sb: identifier. We can write a program that recognizes the subject of each message and constructs a SmarText table of contents (outline) automatically.
Figure 10.11 illustrates the 4-step process to create a table of contents for a document named HypeHype. In the first step, SmarText analyzes the source text file and constructs an ASCII file of commands that define index and cross reference links.
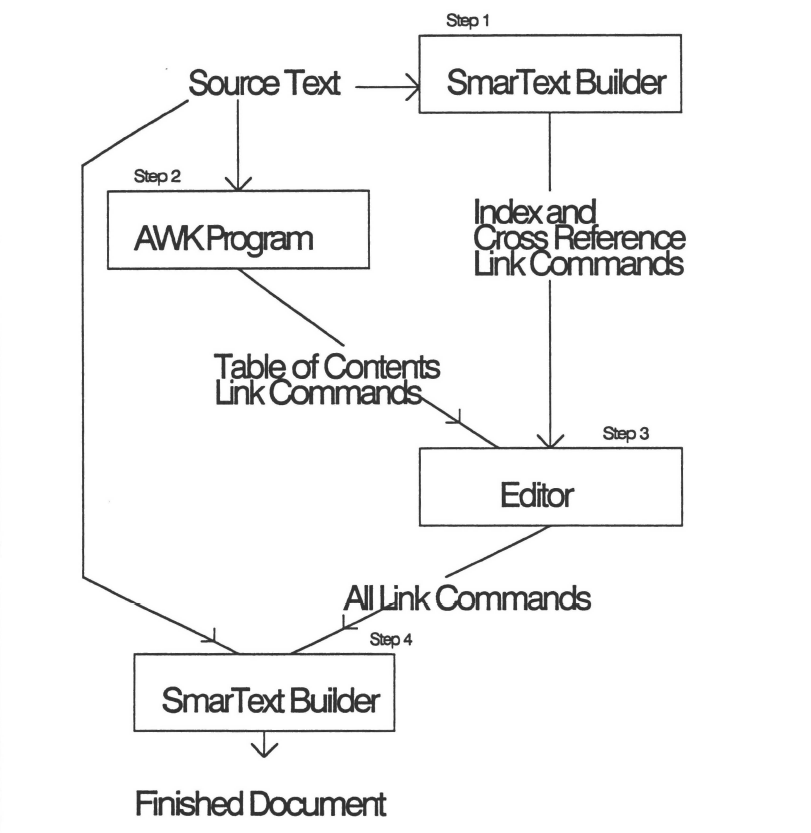
This file is called a shadow file (hypehype.shw). In the second step, commands that define outline links are created using a custom user-written pro gram. This user-written program generates outline link commands that are then inserted into the shadow file using a common ASCII editor (step three). Finally, when SmarText opens a document, it detects that the shadow file has been modi fied (outline links were inserted) and recompiles its pointer database. The result is a fast, custom-built hyperdocument.
The user-written program must create link commands that define links from captions in an outline window to related messages in the text window. To do this, the program constructs a list of SmarText link commands. The link commands needed are typical of those below:
BV HypeHype
T -F1 /1 " HyperHype Update Announced "
T ·F26 /1 " video drivers"
T ·F36 /1 " Help needed converting graphics files"
T -F78 /1 " #6862-HHP to TIFF conversion utility"
T ·F90 /1 " PageDown Crashes HyperHype"
T ·F106 /1 " #Super VGA for HyperHype"
EV HypeHype
The first and last command in the list indicate the beginning and end of a block of commands that define a view with the name HypeHype-BV indicates BeginView and EV indicates EndView. A view is a logical organization of text and outline. The T commands indicate individual table of contents caption entries. The -Fnnn argument indicates the line number to jump to whenever the user clicks on a caption in the outline window. The /n argument indicates the hierarchical level of the caption, where n is an integer from 1 to 9. The quoted string is the caption to be displayed. A complete description of the SmarText command language can be found in SmarText Command Language Application Notes [Big Science Company, 1990].
In order to construct these commands, the user-written program must: 1) identify a subject field delimiter, 2) note the line number containing the subject field,
3) construct a command containing the line number and subject text.
Our link generation program is written in the AWK programming language [Aho, et al., 1988]. AWK is a powerful programming language for manipulating text data. AWK gets its name from its creators: Alfred V. Aho, Peter J. Weinberger, and Brian W. Kernighan. Programmers familiar with the C programming language will see a resemblance in AWK.
The AWK command block that follows the BEGIN command is executed once before AWK processes the input me. (Likewise, an AWK command block that follows the END command is executed once after AWK processes the input me.) All other AWK statements are applied to each line of the input me and have the form:
matchExpression {statement}
If matchExpression evaluates to a non-zero value, then the statement is executed. The AWK program is shown below:
| BEGIN (print "BV SUBJECT";} | # Print BeginView command |
| $1 == "Sb:" | # For each line in the text file, if 1st field matches "Sb: " |
| { $1 = ""; | # then delete first field |
| printf ("T -F%d /1 \"%s\"\n", NR-2, $0); } |
# & print out command |
| END (print "EV SUBJECT";} | # Print EndView command |
In addition to the BEGIN and END statements, two AWK commands are executed in the example above. The second one, the printf command, does all the work. NR is an AWK internal variable that indicates the number of records (lines) read thus far. That value is decremented by 2 so that the line number will reference the beginning of the message. The symbol $0 is another AWK global variable containing the entire text record (line). Since the first field ($1) was set to a null string, $0 contains all text following the first field. The # symbol, like the // symbol in C++, indicates that the rest of that line is a comment.
This simple program can be enhanced in several ways. Alternative views can be constructed based on the date the message was posted, the message originator or the intended receiver of a message. Instead of creating a hypertext table of contents, one could write a program to insert internal cross reference links that would link common messages or threads.
Most SmarText builders will never need to write their own programs to automate the conversion of text into hypertext. However, in specialized applications where custom linking is necessary, SmarText provides access to its internal commands by text manipulation programs.
The AWK programming language was used in this example but any macro or programming language supporting string manipulation could have been used. ICON is one such alternative list and string handling language.
Many word processors like Samna’s Ami Professional and Microsoft’s Word for
Windows also include powerful embedded macro languages.
Summary
Some computer scientists claim that the automatic conversion of linear text into hypertext is an unattainable goal. They may be correct. The conversion of text into hypertext may never become automatic but this chapter has shown several practical ways that it can be automated.
What technologies are most useful for converting text into hypertext?
What hypertext tools are best? Any answer to those questions will have a very short lifespan. The hypertext conversion technology, driven by commercial interests and enabling technologies, is changing very quickly. The best ideas are yet to come.
Footnotes
-
For example, commands that define hypertext links are usually embedded physically in the text. SmarText commands are stored in separate shadow files so that the source text is never physically altered. SmarText commands may be said to be logically embedded.
↵
About the Author
Thomas C. Rearick
Thomas C. Rearick is President of Big Science Company, developers of the SmarText Construction Set being marketed by Lotus Development's Word Processing Division. Mr. Rearick has lectured on hypertext throughout the United States and Europe.Before founding Big Science Company, Mr. Rearick was a Senior Scientist at the Advanced Research Organization of Lockheed Aeronautical Systems Company in Marietta, Georgia. He holds engineering degrees from Duke University and Syracuse University. He is a member of the Association for Computing Machinery, the Institute of Electrical and Electronics Engineers, and the American Association of Artificial Intelligence.
Tom Rearick and his wife Jean live in an Atlanta suburb. They both enjoy caving, rock climbing, canoeing, and backpacking. They have a son, Charlie.
Mr. Rearick may be contacted at Big Science Company, 5600 Glenridge Dr., Suite 255, Atlanta, GA 30342.
References
Aho, A.A., Kernighan, B.W., and Weinberger, P.J., (1988). The AWK Programming Language, Addison-Wesley, Reading, MA.
Big Science Company, (1990). SmarText Command Language Application Notes, Release 1.0, Atlanta, GA.
Bryan, M., (1988). SGML: An Author's Guide to the Standard Generalized Markup Language, Addison-Wesley, Reading, MA.
Conklin, J. (1978). "Hypertext: An Introduction and Survey," Computer, Sept., 1978, 17-41.
Foltz, P.W. (1990). "Using Latent Semantic Indexing for Information Filtering", Conf. on Office Information Systems, Cambridge, MA, 150-157.
Furnas, G.W., Landauer, T.K., Gomez, L.M., Dumais, S.T. (1983). "Statistical Semantics: Analysis of the Potential Performance of Keyword Information Systems," Bell System Technical Journal 62(6), 1753-1806.
Goldfarb, C. F. (Ed.), (1986). "Information Processing-Text and Office Systems-Standard Generalized Markup Language (SGML)," Int'l Standard ISO 8879. Int'l Organization for Standardization, Geneva.
Salton, G. (1989a). Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer, Addison-Wesley, Reading, MA.
Salton, G. (1989b). "On the Application of Syntactic Methodologies in Automatic Text Analysis", Proceedings of 12th Int'l ACMSIGIR Conf. on Research and Development in Info. Retrieval, Cambridge, MA, June, 1989, 137-150.
Shneiderman, B. (1983). "Direct Manipulation: A Step Beyond Programming Languages," Computer, August 1983,57-69.
Shneiderman, B., Kreitzberg, C., Berk, E. (1991). "Editing to Structure a Reader's Experience," in Hypertext/Hypermedia Handbook, Emily Berk and Joseph Devlin (Eds), McGraw-Hill, New York, NY.