9
Automated Conversion
Introduction: The Decision to Automate
The ever-growing amounts of information being generated in fields as diverse as medicine, engineering, maintenance and law require us to develop means of organizing information in ways which support rapid retrieval.
Forty-five years ago Vannevar Bush realized that:
The difficulty seems to be not so much that we publish unduly in view of the extent and variety of present-day interests, but rather that publication has been extended far beyond our ability to make real use of the record. The summation of human experience is being expanded at a prodigious rate, and the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships. [Bush, 1945]
This problem has only gotten more acute with the development of personal computers; text editors and database managers have provided the means to create ever-increasing amounts of information.
Businesses are becoming increasingly dependent upon efficient access to this huge volume of information. A critical element in the movement to highly interactive information systems is our ability to take the massive amounts of already existing information and convert it for use on interactive computer systems.
Paper-Based Authoring
Businesses generate paper-based documents by amassing information and then organizing its presentation. This organizational process may require a great deal of effort.
For technical or reference documents, features such as tables of contents, indices, and page and section numbering have all been developed to help readers find information in paper-based presentations in nonlinear ways; that is, without having to read sequentially through entire texts. The table of contents allows readers to see the basic structure and organization of a document. An index provides readers with a list of topics that might otherwise have to be searched for. Both the table of contents and the index help readers to identify items of interest and then rapidly access them.
Many people see hypertext as a means of avoiding or overcoming the creative
limitations imposed by the linearly structured paper presentation medium. Yet, in many cases, a great deal of effort has gone into the construction of searching support tools such as tables of contents and indices; this effort should not be discarded when considering converting paper-based information to hypertext.
Rationale for Conversion
Converting an information resource into hypertext involves much more than simply creating a computer-readable version of the text and graphics. Converting involves:
- Selecting documents which would benefit readers if they were in hypertext form
- Determining how to convert them
- Producing process-ready computer files from paper or other forms
- Specifying and identifying what should be linked
- Performing the conversion and verifying the results
Manual vs. Automated Conversion
There are two basic means of converting existing documents into hypertext. One is manual conversion. This involves selecting a hypertext authoring tool and then entering the document into that environment manually and constructing all of the links as you convert the pages. Hypertext authoring has all the perils of any authoring; the organization and flow of the information is in the hands of the author and it’s then up to the reader to deduce that structure.
Another major problem with manual conversion is the inducement of human error. In a manual conversion, decisions regarding what should be linked and where a link should go are made by human operators and therefore subject to individual interpretation. This might be valuable for the true author who is constructing new information, but for a conversion it can be a disaster. In fact, the repetitiveness of the chore of constructing links in existing materials can lead people to error while repetitive tasks are what computers do best. The goal of most conversions is an enhanced but true reflection of what is in the original document. With automated conversion what is linked and where links go is specified up front and therefore verifiable. After a document has undergone automated conversion, a human author may be able to add links beyond those that current conversion software would implement.
There is an interesting parallel between the current state of hypertext conversion
and the early days of Computer Assisted Instruction (CAI). In the early days of CAI, a great number of companies produced and marketed CAI authoring tools. Initially, many of their clients began converting their curricula to this new delivery environment. Once the prototypes and/or initial projects were completed, and they had both evaluated the level of effort involved in converting a short lesson (maybe an hour long) and extrapolated that level of effort to converting an entire course, they often abandoned CAI entirely. The anticipated effort simply was not worth it.
The same story can be told about manual conversion of documents into hypertext. Many people are investigating hypertext and are interested in getting their information into this new form. Manual conversion works for small prototype projects. But when you scale up from converting a few pages or even a few dozen pages to converting tens of thousands of pages, manual conversion becomes unthinkable. A perfect example is a reference text which has an index of over 50,000 items. If you could manually insert links at one a minute, it would take over five months to construct just the links for the index of this one book. For several years now, the Hypermedia Systems & Services organization at Texas Instruments Incorporated has been developing computerized tools to do this type of conversion.
The PEAM Experience
The Personal Electronic Aid for Maintenance (PEAM) program is a historical case in point. In the early 1980s the Department of Defense undertook a multi-phase research project aimed at developing a portable system to aid maintenance technicians in performing maintenance tasks [Personal Electronic Aid for Maintenance (PEAM) Final Report, 1981].
Realizing that paper documentation could not be used because it was too bulky, often out of date, and often not available, the Personal Electronic Aid for Maintenance program was undertaken. The goal was to come up with a conceptual design for a portable electronic device which could provide technicians with accurate technical information on demand.
The program was begun in 1980 by Texas Instruments and the XYZYX Information Corporation, and funded through the Army Project Manager for Training Devices (and later the Army Research Institute for the Behavioral and Social Sciences) and the Naval Training Equipment Center.
Initial prototypes delivered in 1985 contained a flat panel display, a memory storage module, and speech input and output devices, all contained in a briefcase-sized unit. Users' interaction with PEAM was through a limited set of commands which could be entered via function keys or speech. With only eight commands (next, last, select, backup, yes, no, menu, and speak) users could navigate throughout an electronic maintenance manual. This system incorporated hypertext navigational properties to assist technicians in locating necessary information.
Early on, it was recognized that the information in the current paper maintenance manuals was going to have to be transformed somehow into interactive units capable of display and manipulation. The approach was to construct a hierarchical set of Job Performance Aids (JPAs). While this was not referred to as hypertext, it had all of the primary characteristics: the information was contained in small units, these units were connected and the user moved between or among these units via the connections. The issue faced by the PEAM program was how to convert existing maintenance manuals into the interactive units. What was learned was that at that time there was no automated process available to support this conversion. Converting a single manual by hand was possible for the tests. But even using their sophisticated computer tools, it would be prohibitively expensive to do all military manuals that way.
Once the prototype units were completed, an independent group was commissioned to test the utility of the PEAM concept. The system was evaluated under both Navy and Army environments. The Army evaluation used the maintenance procedures associated with a subassembly of the turret assembly of the M-1 Tank and the Naval with the NATO SEA SPARROW Surface Missile System.
In the Army test, a group of qualified M60 Tank mechanics was split in two. One group was trained on how to use the paper manuals for the M-1 tank and the other was trained on how to use an emulator of the PEAM device. Once the training was complete fault conditions were introduced into a tank simulator and the mechanics were instructed to troubleshoot the faults. In the Navy test, a single test group was used but this group was made up of individuals who ranged from experienced technicians to individuals with no technical training at all.
The Army test results showed an almost 3:1 reduction in troubleshooting errors with the PEAM system. The Naval test results showed an almost 6:1 reduction in troubleshooting errors with the PEAM system [Wisher and Kincaid, 1989]. In the Army test it took several days of training for the group that used hardcopy manuals to learn how to use the M-1 while the PEAM group was trained on how to use the device in a matter of minutes. An interesting observation from the Naval study was that there was little performance difference between the experienced technicians and the inexperienced technicians who used PEAM.
Two major lessons were learned from PEAM. First, while the PEAM program appeared to validate the utility of the hypertext approach to organization and delivery of information, it did not overcome the problem of converting large volumes of existing information into hypertext. Second, the potential effectiveness of the PEAM concept became clear.
Detailed Procedures Involved in Conversion
In order to successfully port information from paper to hypertext, it is necessary to understand the nature of the information involved. In particular, we must concern ourselves with factors involved in the original creation, display and the intended use of the information in its current form.
Many written texts are prepared and accessed in a linear format: that is, text is normally read from the first page to the last in sequential order. This format supports the presentation of information as a series of related events occurring in a chronological order. Entering many books at a point in the middle is generally neither very informative nor entertaining because it violates the intended linear process of presentation. The fundamental structural element for this approach is the page number. Page numbers provide both the sequential order to the printed text and a mechanism which allows readers to enter and re-enter books over several readings.
However, technical reference materials are not read in the same way as other books. These materials typically are highly cross-referenced and in fact are not used in a linear fashion. Documents of this type incorporate various types of structures. These include: one or more table of contents; chapters; numbered sections and/or paragraphs; section and/or paragraph titles, indentures or other identifiers; and various internal and external reference schemes.
Each of these structures helps readers access a document in a nonlinear fashion. That is, specific parts of the document can be located quickly without the need to read all the preceding parts. Automated conversion methods should take advantage of structures created by the writers, technical editors, and indexers of original documents. The Texas Instrument HyperTRANS facility was devised to identify and utilize all of these structural and contextual elements and use them in automatically building hypertext documents.
What Does Automated Conversion Do?
Creation of a hypertext document involves deciding how to partition the information: what should constitute a chunk or node; what types of nodes and links are required; which nodes should be linked to which and by what type of link; and so on. Because of these options, and the repetitive nature of the task, manual conversion is time-consuming and prone to error. The Texas Instruments HyperTRANS system was designed to automate link identification and construction.
Rather than just a stream of characters, a document is comprised of paragraphs, illustrations, graphs, lists, tables, sections, and chapters. An automated conversion system must be able to recognize these structural elements, determine which to treat as hypertext nodes and then construct the appropriate links to form the hypertext network. Some links capture the hierarchical structure of the document; for example, a section is linked to its parent chapter and any subsections become the section's children. Other links connect figure references to their figures, glossary or index entries to the places they occur in the document, concepts to related concepts, and so on. Any node can be linked to any other node, even nodes in other documents. This can become a critical aspect of conversion because often written material comes in sets or groups which reference each other. This can be seen in “User,” “Reference” and “Technical” guides which accompany hardware and even some computer software packages. Often discussions in one document refer readers to one of the other documents for greater detail or definitions or procedures.
The Steps Involved In Automated Conversion
The procedures involved in successful automated conversion are described below.
Selecting Appropriate Materials. The first step in automated conversion involves selecting appropriate documents for input. Of primary concern when evaluating a document for conversion is the nature of the information and the target audience for the hyperdocument.
Some types of documents, while they could be converted, would not benefit from conversion. A novel, for instance, might be convertible but readers would probably not obtain any real value from having it converted.
Information that, in print, is approached in a nonlinear fashion is likely to benefit from conversion. These kinds of printed documents include encyclopedias, maintenance manuals, parts catalogs, etc. Educational and technical reference books used to find specific items of information are also good candidates for conversion.
Some believe that the information in its written form needs to be in many relatively short pieces which are cross-referenced to be a good candidate for automated conversion [Furuta, Plaisant and Shneiderman, 1988]. While this is nice to have, not all candidate documents meet this requirement.
The conversion algorithm must be adaptable to both deeply- and broadly-structured documents. A broadly-structured document, an encyclopedia, for example, contains a large number of individual articles many of which can be linked. Many technical manuals, on the other hand, may have tables of contents with 5, 6, or even 7 levels of indenture, thus indicating a very deep structure. Many good candidate documents have very deep structures in addition to being highly cross-referenced.
Documents which are deeply-structured can be difficult to use in paper form, and they may be harder to convert into hypertexts, but they can be made highly useful in hypertext form.
Any document or set of documents is a good candidate for conversion if it is information-rich, highly cross-referenced, or has a complex, well-defined structure. Documents of this description include: business proposals, maintenance manuals, programming manuals, military or corporate standards, textbooks, technical references and so on.
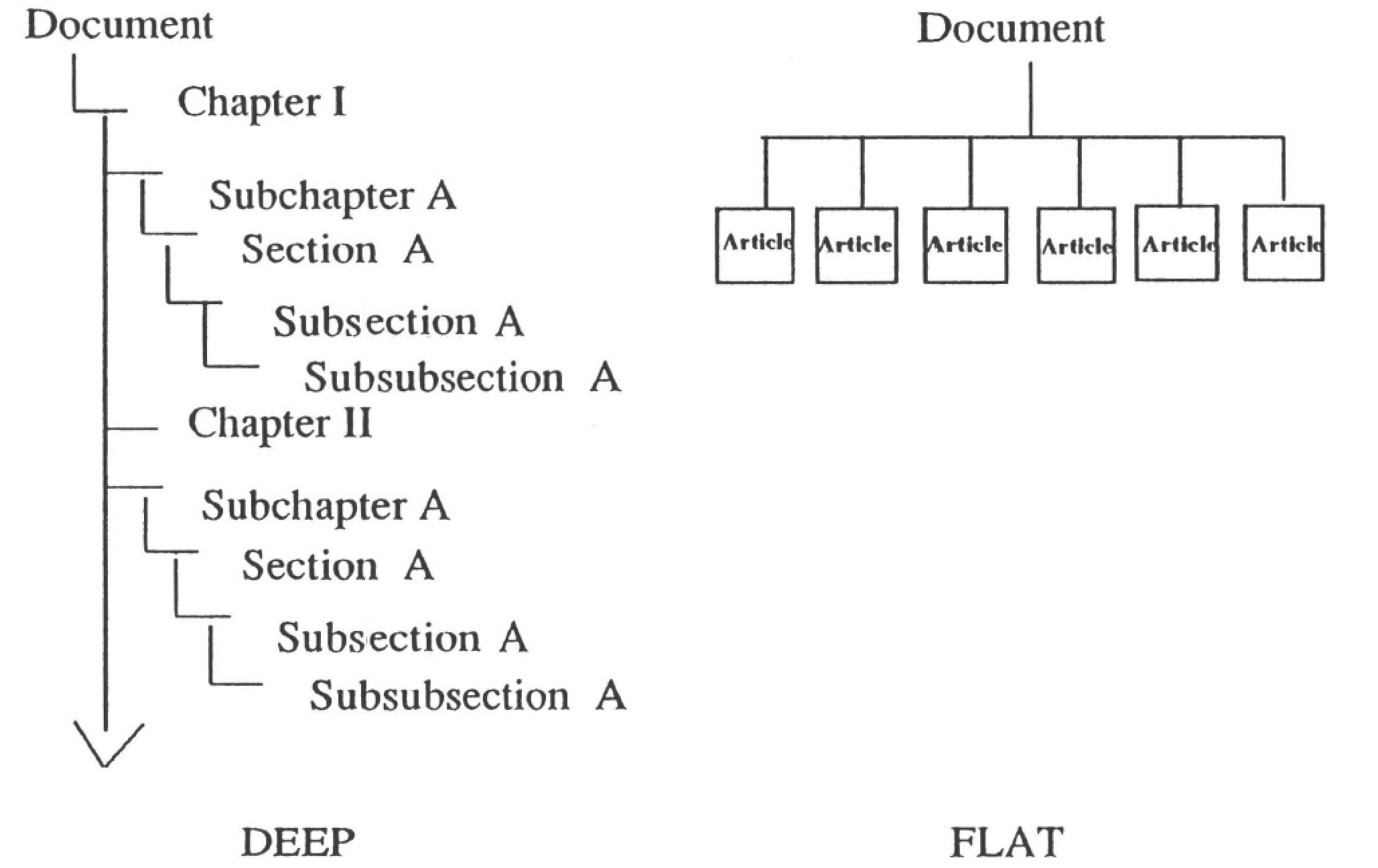
Documents which have reasonably consistent formats and use technical vocabularies make ideal candidates for hypertext conversion.
Elements to look for in selecting candidate documents include:
- Does the use of the document lend itself to hypertext?
- Is there an explicit or implicit structure?
- Does it have a table of contents or can one be extracted or derived?
- Does it have an index, glossary, etc.?
- Is it highly cross-referenced either internally or externally?
- Are there definable units which can be linked?
The Texas Instruments HyperTRANS process is applicable to many different types of documents.
Selecting and Configuring the User Interface. Many of the currently available hypertext systems are frame-based. These tools equate a node or frame to the information which can be displayed on a single computer screen. Frame-based authoring tools are appropriate for most authoring because authors can think and create units of information in screen or frame sized units. But existing written information does not always translate easily into screen-sized units. Frame-based interfaces can require significant reformatting of materials for display purposes.
File-based hypertext systems do not impose the same restrictions on node size as frame-based systems and thus can be easier to convert to. In one type of file-based system, the complete textual information is contained in one (or a series of) text files similar to a set of word processor text files. Link information is stored in a separate set of files and contains information about where links point into the text file(s).
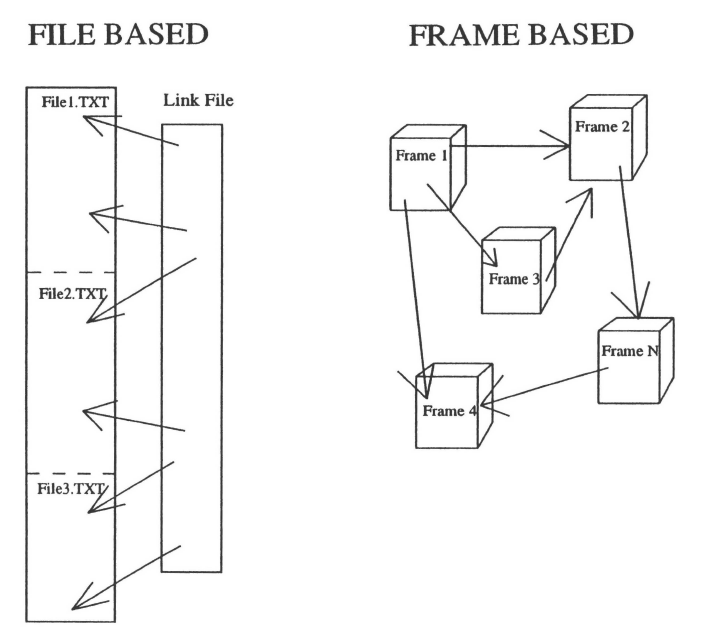
For example, the Texas Instruments DISCOVER… interface is not limited in terms of the size of the chunks (or nodes) of information. By keeping the link information separate from the nodes and being able to link to elements that might be within a chunk or node, the interface can handle information with virtually any size units. This file approach also supports a look-and-feel similar to the original paper document.
Another aspect of the user interface involves how the information is intended to be used. Authors of technical reference manuals often do not want readers to have access beyond browsing or looking at certain information. If it is important that maintenance personnel all follow the same procedures, then it is important that they not be able to modify the information in any way.
Sometimes it is important that readers not change the information but it is also useful for them to be able to add personal or local comments as annotations to the original information. This annotation capability can go so far as adding additional personal links.
Even in its paper form, a manual is rarely ever error-free and often a person using a manual can find better ways of performing a task than is specified in the maintenance manual. Providing a means of identifying, capturing and then redistributing this information can significantly improve the hyperdocument. These locally-generated annotations and links can be captured as a source of feedback to the authors of the information. This can be especially useful with maintenance manuals.
Once a document has been converted to hypertext, the original authors will
recognize additional links and changes which they would like to make. Hypertext provides the ability to display and manipulate relationships which can give an author cues to other items which could be related. If they have to go through the painful process of manual conversion, they may never get to the point of analyzing and identifying these additional relationships. Providing them a rapidly converted version of their materials gives them a base from which they can embellish the information using a manual hypertext authoring tool.
Another consideration is whether there is a need to return to a print form of the
information from the hypertext database. If editing and printing are elements of the complete system, then keeping the text in some ASCII or other native form with as little added mark up in the files as possible makes editing and printing the information easier.
Display Environment Considerations. An additional consideration in conversion is the target display environment. If the information is very voluminous and/or contains a large number of colors or highly complex graphics, it will impact both on the end display environment and the conversion process.
Large complex graphics, multiple text fonts and the like may dictate high resolution or graphics monitors for display, mass storage devices (such as CD-ROM
drives), or input devices (e.g., a color scanner).
High quality print images may achieve resolutions of up to 1200 dots per inch while a very good computer screen can display the equivalent of only about 100 dots per inch. This disparity means that printed images that are scanned into hypertexts may become unreadable on a typical computer screen. Of course, the hypertext builder may decide to show only a portion of each high resolution picture on screen at a time. In addition, printed images may contain so much detail that in displaying them, the ability to zoom in, pan and/or scroll through the image becomes necessary. These decisions can have a major impact on the document conversion process.
Handling Graphics. Give serious consideration to the display requirements for graphic images being imported.
- Is it imperative that the same level of clarity that was on the printed page be maintained for computer display?
- Is it acceptable to reduce the size of the images (using graphics tools or utilities)
so that each can be displayed, whole, on a single screen? - Are there elements in the graphics which should be linked to other graphics or to text?
Answers to these questions can have a major impact on the procedures used to import images into the hyperdocument. The same kinds of issues must be addressed relative to other print attributes and their conversion to computer display. If the document contains multiple fonts or other attributes, is it acceptable to convert these to computer-displayable alternatives? If not, if displaying the font attributes on screen exactly as they appear on paper is critical, then the conversion process will undoubtedly involve weighty graphical design considerations.
Typically, printed illustrations are converted from paper by means of scanning or frame grabbing from the paper originals. Frame grabbing refers to the process of capturing the image with a video camera and then digitizing a single (still) frame of the video. These scanned or grabbed images are usually converted into raster or bitmapped images which are then displayed using a graphics display utility. The amount of adjustment images require for display will determine how much human intervention will be required during the conversion of printed and graphical elements.
Many technical manuals include call outs or other identifiers which are integrated into a graphic and reference some other graphic or piece of text. A conversion process must include the ability to handle these types of links, preferably without having to reconstruct the graphic. Many current hypertext tools provide utilities for importing and manipulating graphics. However, there are, in general, fewer tools that facilitate linking to and from graphics.
Converting Source Text Into Machine Readable Formats. Before text can be converted into hypertext, it must be available in computer-readable form. There are two basic ways of getting textual materials into a format that can be processed by the automatic conversion software. One is to scan in original paper pages; the other is to convert already-existing computer files.
Scanning: Documents which are available only on paper must be scanned in in order to be converted into computer-readable text. It is often the case that even when computer files exist, the paper version of the document is the most correct or accurate version of the information. For example, some physical “cut-and paste” processes or last minute editing corrections to galley proofs may have resulted in changes to the printed document that never have been incorporated into the computer files.
A great deal of effort has to go into analyzing the document before scanning occurs. Scanners and their support software are geared toward capturing “pages” of information primarily for storage and reprinting them on paper. Scanning technology is not geared toward preparing text information for computer display. Thought must go into deciding how to separate and store information input via the scanner to facilitate the automation process.
The basic scanning procedures include:
- Bound material is unbound or photocopied;
- Each page is scanned to produce a bit-array image;
- The images are split into sub-images containing either text only or graphics only; and
- The text-only images are sent through an optical character recognition (OCR) program to extract their individual ASCII characters.
In some instances it is to useful to retain the image version of complete pages for display purposes but the ASCII version of the text characters is still necessary for link identification.
Not all procedures in the hypertext creation process can be fully automated.
Scanning is one of those procedures. Since no image scanner is 100% accurate, the resulting files must be proofread and scanner-induced errors must be corrected. Some text images are difficult to convert into text characters due to poor print quality, low contrast between ink color and paper color, small or complicated typefaces, or other reasons. Also, OCR algorithms often have trouble with items such as underlining, boldface, italics, and other print enhancements or character attributes. Using the scanner usually saves a great deal of time and effort, but for some documents, a skilled typist’s manual input is actually faster.
High-quality graphics may also benefit from a human touch. Using a graphics package, elements of graphic images can be touched up. For example, an area that should be solid black but has a few white pixels, or a line that should be continuous but appears broken can be fixed manually. The amount of operator time required for scanned text and graphics varies from document to document and application to application.
Translating existing computer-based text files: A format conversion utility is
customarily used to translate existing computer files into a standard format acceptable for hypertext conversion. Some currently available page layout or formatting utilities are not recommended because they were designed to produce pages to be printed on paper and thus converting their native files to hypertext-processible forms is extremely difficult.
If a conversion utility is unavailable for a particular format, one of two processes must be applied to produce process-ready files: develop a format conversion utility or print the document and then scan it in using an OCR program to convert the bitmapped scanner image into text.
Creating the Document Description. A document typically contains a table of contents, a list of figures, a bibliography, a glossary, an index, and so on, but these can exist in many possible formats. Typically the conversion facility must be informed about the specific formats used by a given document or set of documents. The TI HyperTRANS facility recognizes many formats, but new formats are inevitable. When a new format is encountered, HyperTRANS must first be taught the distinguishing characteristics of the unfamiliar formatting style. This requires a programmer or technician to create a document description. The document description tells HyperTRANS which formats are used in the document. The document description will provide HyperTRANS with information such as what a typical line in the table of contents looks like, what the format is for an entry in the document's index or glossary, how to recognize figure references, internal cross references, or references to other documents, etc.
Once a document description is available, HyperTRANS can search the document for visual and spatial cues, attributes, or other features that will help it to identify the document’s various internal structures and links. Once a document description has been generated, it can be used for any document with the same format. When an entire set of manuals with a consistent style needs to be processed, only one of these documents needs to go through this document description step. All of the others can be processed using the same document description.
Subtle elements in a document can have a significant effect on the efficacy of
the automated conversion. For example, an author may use a reference such as “see Paragraph 1” when there are several Paragraph ls in the document. There might even be a Paragraph 1 in every chapter in the document. In these ambiguous cases, a reader would use context cues to determine which Paragraph 1 the author really was referring to. Occasionally the automated conversion process must possess the same capability. HyperTRANS extracts information about such ambiguities by analyzing the document and also relies on the document description file.
Creating View Descriptions. The same body of information can be of value to many different readers. It might be made more useful if it is organized for them. Even the same reader may look at a hyperdocument with a different view at different times. For example, a typical repair manual can contain a training view, a troubleshooting view, a routine maintenance view and a purchaser's view. Each view can be seen as a filter; information not relevant to a particular reader should be filtered out. An expert might not be shown training information, a service mechanic would see maintenance procedures and a purchasing agent would see part names, numbers, quantities and prices. View descriptions can be created for any group of readers which can be described. View descriptions may appear as alternate tables of contents or structural organizations to the information. Details about the target reader group need to be specified prior to actual conversion in order for the view descriptions to be defined.
Initiating the Conversion Process. After the computer-readable files of a document have been created, they are stored in one or more text files and bit-mapped graphics files. An additional file may be required which contains a short description of each graphic (such as “Figure 12-4,” Diagram 5,” or “Photo of Part A1B2C3”), along with the name of the file where the graphic is stored. At that point, for the TI HyperTRANS process, the text file(s), the file containing the graphic descriptions, the Document Description file and any View Description information are fed to a batch process. The batch process includes functions for identifying (or marking) the links and building the links. The process must be capable of:
- parsing (chunking) the input documents into nodes;
- building hierarchical links based on the division of the document into chapters, sections, subsections, etc. This may involve using the existing table of contents or generating one automatically if needed;
- building associative (non-hierarchical) links among the document’s nodes based on references to: chapters, sections, figures and tables, key phrases, index and glossary entries;
- building associative links to other documents (external links) based on cross references.
Errors in Input Documents. There are a variety of issues which automated conversion must be able to handle. Among these is how to deal with errors in original documents. In working on over 50 conversion projects Texas Instruments Hypermedia Systems & Services has not yet processed a document in which we did not uncover errors. These could be as simple as a typographical error or a misspelling or something much more serious such as total inconsistency in structure. The HyperTRANS process has been designed to uncover all kinds of errors in the material which it is fed.
When HyperTRANS encounters a problem while processing a file, it describes the problem in an output file called an Exception Log. Each log entry indicates the exact location in the document where the problem occurred as well as which HyperTRANS module was executing at the time. The types of problems reported by HyperTRANS include errors in the document description and errors in the document itself.
Typical types of errors which HyperTRANS uncovers are:
- inconsistent names or numbering;
- missing figures, tables, captions, etc.;
- missing footnotes, bibliographic notes, etc.;
- index entries not found in text;
- unreferenced items.
Each error must be resolved before a complete hyperdocument can be produced. Errors in the document description are corrected before the document is reprocessed. Errors in the original document may require consultation with the author of the document. Correcting them may require no more than a typographical change, or a major structural change or rewrites of portions of the document may be required.
Completing the Conversion. Once all the errors have been resolved, the completed hypertext database must be checked and verified. Algorithms can be applied to ensure that there is an origination and destination for each link. Human review is required to check content-related linking. The utility of any given link is often a subjective decision and typically is left up to the original document authors or readers. It is also through this review and validation process that content specialists often identify both better ways to write the paper manual and ways to improve subsequent versions of the hyperdocument.
Processing the Materials for the End Environment. Once the hypertext database has been created, you have to process the information for the desired reader environment. Unless the conversion facility is closely tied to a user interface, what comes out of the convertor is information about the text, graphics and hypertext links which then has to be translated into the required format for the desired interface. This may involve writing software to implement the desired user interface using the text, graphics and links generated by the automatic conversion. This is where the issues relative to frame vs. file based systems come into play. Also, issues concerning text vs. graphic based interfaces are important as well as the basic metaphor employed by the interface. The flexibility (or lack there of) of the user interface has a major impact on the ability to automatically translate documents for the interface.
Packaging and Distribution. Once the hyperdocument has been created, it will be distributed to readers. The medium for distribution is chosen based on the size of the hyperdocument and the computer and peripherals readers own. Critical concerns for distribution involve the number of readers and the volatility of the database. Rapid and frequent changes probably suggests a centralized database which readers can access.
More static documents which require periodic updating and maybe support a large number of displaced users probably suggests some type of CD-ROM. Small documents can be distributed to individuals on diskette. Larger databases may require a CD-ROM or other large capacity mass storage device. In some instances a single copy of a document can be shared via a local area network or other communication approach.
Open Issues for Translation
A variety of issues pertaining to automatic conversion remain to be worked out. Some of these are issues for hypertext in general. Among these are hypertext standards, the role of hypertext in solving bigger problems and the nature of information organization.
Standardization
Standardization implies some agreed-to concepts, principles or guidelines. Currently, there are efforts underway to develop standards for hypertext but none have, as yet, been accepted and implemented by the growing hypertext community. If you select a particular hypertext tool or interface for your work, you have no guarantee at present that what you develop will be compatible with what others develop. This provides both an opportunity and a problem for those doing automated conversion. First, it means that it may not be simple to convert one hyperdocument format to another and thus it will provide work for those who want to create these translators. But more importantly, it means that each hypertext tool which is created need not comply with anything which would make automated conversion easier. [See Chapter 26 on Standards in this book.]
Hypertext As Part of a Solution
Converting information into hypertext in most instances should not be viewed as a stand-alone exercise. Information access is typically tied to some larger problem which someone is trying to solve. Whether it be better education, or more effective maintenance, or more timely business decisions, the use of hypertext for information access must be placed in context.
Often technologies come along which people attempt to use to solve all of their problems.
Hypertext is a relatively new idea which has not yet matured and, therefore, its boundaries of application have not been thoroughly tested. While this means that hypertext may well prove valuable in areas as yet untried, it also means that there are places where it is not the best solution and we need to identify and communicate these as well.
Additionally this means that in order for a hyperdocument to be truly useful, it must be able to interact with other software. For example, a parts and service hyperdocument may interact with parts ordering and inventory software.
Information Organization
Hypertext environments allow writers to produce information in a haphazard way and then link the information later. While this provides some very exciting opportunities for creative writers it also poses some potential problems. Effective writing (especially in technical areas) is often a difficult and time consuming activity. Having information technically correct is only part of the problem. What often takes the most work is identifying the best organization and structure to apply to the information and then being disciplined enough to consistently apply the organization. Without effective discipline, the hyperdocument creator can produce a very useless document. Organization and structure are critical elements to information transferal, regardless of the medium.
Conclusions
Hypertext provides an exciting addition to the traditional means of information access and manipulation. With the growth of computers, the creation of forms of information storage and retrieval have had an equal opportunity to grow. No
longer are we limited to the printed page as a means of conveying information. Just like the spreadsheet really extended the "calculator" to take advantage of the computer, so can hypertext extend the written document to take advantage of the computer.
Hypertext authoring tools provide the means of creating this new form but to
really provide the momentum for this new concept we must find ways of moving vast amounts of already existing information into hyperdocuments. To accomplish this, automated conversion programs are needed.
Automated conversion is necessary for a variety of reasons. First and foremost
is simply the size of the problem. The amount of existing information which could benefit from being converted is staggering. Manual conversion is simply too slow, imprecise and costly to be effective.
Finally, for hypertext conversion to be effective, we must leverage what has gone on before. While hypertext provides us the means of extending our information transfer opportunities, we should not ignore what already exists. It has been our experience that good hypertext requires/reflects good organization. Well written, well structured, well organized documents make for good hypertext. Poorly written, poorly organized information makes for poor hypertext. Those involved in creating this new technology should build on the legacy of authors who have gone before.
About the Author
Robert W. Riner, Ph.D.
Robert W. Riner, Ph.D., is currently the Marketing Director for the Hypermedia Systems & Services organization at Texas Instruments. In that capacity he is responsible for interacting with customers to assess information management needs and to see where the TI HyperTRANS process can solve customer problems. Prior to his current position he was on loan to the Computer Learning Research Laboratory at the University of Texas at Dallas where he was involved in research focused on the application of artificial intelligence and hypermedia to education and training. For 15 years, he has been involved in the development and application of advanced technologies to improve human productivity. He has a Ph.D. in instructional design from Florida State University.Mr. Riner may be contacted at Hypermedia Systems and Services, Texas Instruments, Inc., P. O. Box 650311, MS 3968, Dallas, TX, 75265.
References
Bush, Vannevar (1945). "As We May Think. " The Atlantic Monthly 176.1 (July) p. 101-103.
Devlin, Joseph. (1991). "Standards for Hypertext," in Hypertext/Hypermedia Handbook, Emily Berk and Joseph Devlin (Eds), McGraw-Hill, New York, NY.
Furuta R., Plaisant C. and Shneidennan B., (1988). A spectrum of Automatic Hypertext Constructions. Hypermedia, Vol. 1 No 2, 179-195.
Personal Electronic Aid for Maintenance (PEAM) Final Report, (1981). Prepared for the Human Factors Laboratory, Naval Training Equipment Center and The Army Project Manager for Training Devices (Contract NO. N61339-80-C-0134), August.
Wisher R. and Kincaid J., (1989). Personal Electronic Aid for Maintenance: Final Summary Report, Army Research Institute, March.